When juggling lots and lots of connections, the overhead of the select() call becomes important. Imagine you have 1000 clients connected to your server, but they're slow. A single client sends you a request - which you handle, and now you're at the top of poll() again. This causes all 1000 objects to have their readable() and writable() methods called. The end result of this is that after a few hundred connections, your CPU usage will be pegged because you're churning the polling loop wastefully.
So I've tweaked a few things to cut down this overhead...
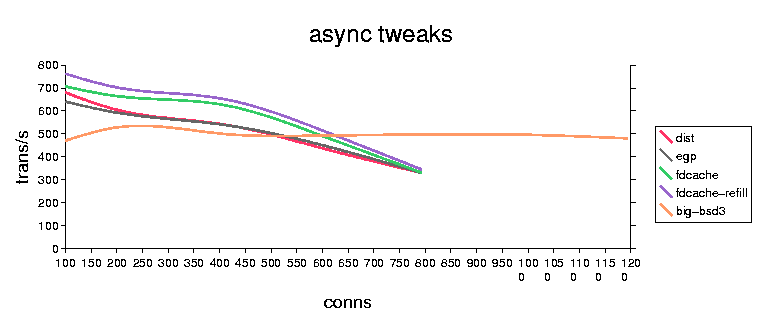
The test is medusa/test/test_lb.py, with a 64-byte 'packet', 20 packets per connection. Server and client on the same machine, using the loopback address (127.0.0.1). The number on the graph is 'transactions/second'. The tests were run on RH6.1,linux 2.2.12, K6-2/350.
The tweaks appear to be a win... maybe 15%-20% or so? The bsd performance is pretty bad (especially considering the difference in CPU's) but is probably an artifact of the loopback implementation.
There still remains the overhead of the readable() and writable() methods, I'm not sure what can be done about it... ideally we would like to have the object carefully manage the state of an attribute rather than requiring a method call. But I don't think this can be retrofitted without breaking everything.
At eGroups we have a coroutine-based system (that I will release any day now, I promise!) that doesn't have this overhead, because each coroutine 'blocks' on a specific condition, they're not polled by the loop. We also have the asyncore-like bits implemented in C and talking to poll(2) rather than select(2).
BTW, the graph was generated using StarOffice. Way Cool.