a.k.a. event-driven programming or select()-based multiplexing, it's a solution to a network programming problem: How do I talk to bunch of different network connections at once, all within one process/thread?
Let's say you're writing a database server that accepts requests via a tcp connection. If you expect to have many simultaneous requests coming in, you might look at the following options:
fork() is the Unix
programmer's hammer. Because it's available, every problem looks
like a nail. It's usually overkill
With async, or 'event-driven' programming, you cooperatively schedule the cpu or other resources you wish to apply to each connection. How you do this really depends on the application - and it's not always possible or reasonable to try. But if you can capture the state of any one connection, and divide the work it will do into relatively small pieces, then this solution might work for you. If your connections do not require much (or any) state, then this is an ideal approach.
pros:
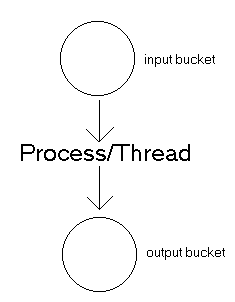
Here's a good visual metaphor to help describe the advantages of
multiplexed asynchronous I/O. Picture your program as a person, with
a bucket in front of him, and a bucket behind him. The bucket in
front of him fills with water, and his job is to wait until the bucket
is full, and empty it into the bucket behind him. [which might have
yet another person behind it...] The bucket fills sporadically,
sometimes very quickly, and sometimes at just a trickle, but in
general your program sits there doing nothing most of the time.
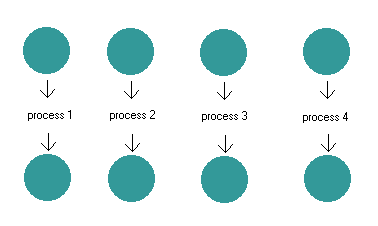
Now what if your program needs to talk to more than one connection (or
file) at a time? Forking another process is the equivalent of bringing
in another person to handle each pair of buckets. The typical
server is written in just this style! A server may be handling 20
simultaneous clients, and in our metaphor that means a line of 20
people, sitting idle for 99% of the time, each waiting for his bucket
to fill!
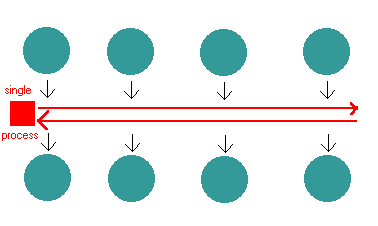
The obvious solution to this is to have a single person walk up and
down the aisle of bucket pairs. When he comes to a bucket that's
full, he dumps it into the other side, and then moves on. By walking
up and down the aisle of buckets, one busy person does the job of 20
idle people.
The only time when this technique doesn't work well is when something other than just dumping one bucket into the next needs to be done - say, turning the water into gold first. If turning a bucket of water into a bucket of gold takes a long time, then the other buckets may not get processed in a timely fashion. For example, if your server program needs to crunch on the data it receives before responding.
Now how do we apply our bucket wisdom to network programming?
Depending on the operating system, there are several different ways
to achieve our 'bucket-trickling' affect. By far the most common, and
simplest mechanism uses the select() system call. The
select() function takes (in effect) four arguments: three
'lists' of sockets, and a timeout. The three socket lists indicate
interest in read, write, and exception events for
each socket listed. The function will return whenever the indicated
socket fires one of these events. If nothing happens within the
timeout period, the function simply returns.
The result of the select() function is three lists
telling you which sockets fired which events.
Your application will have a handler for each expected event type. This handler will perform different tasks depending on your application. If a connection has a need to keep state information, you'll probably end up writing a state machine to handle transitions between different behaviors. Diving back into the bucket [paradigm], these events might be the equivalent of adding little "I'm full now" mailbox-like flags to the buckets.
Animating the server using select() is easy: A simple
event loop will suffice. I usually use a loop with a 30-second timeout.
That way, I can do any necessary housekeeping tasks at least every 30
seconds.
[Note: for those of you coming to this page through an Internet search engine, the following description is of a library written in Python.]
Well, lucky for you, there's a set of common code that makes
writing these programs a snap. In fact, all you need to do is pick
from two connection styles, and plug in your own event handlers. As
an extra added bonus, the differences between Windows and Unix socket
multiplexing have been abstracted - using the async base classes
(asyncore.dispatcher and
asynchat.async_chat) - you can write asynchronous
programs that will work on Unix, Windows, or the Macintosh (in fact,
it should work on any platform that correctly implements the
socket and select modules).
The first class is the simpler one,
'asyncore.dispatcher'. This class manages the
association between a socket descriptor (which is how the
operating system refers to the socket) and your socket object.
dispatcher is really a container for a system-level
socket, but it's been wrapped to look as much like a socket as
possible. The main difference is that creating the underlying socket
operation is done by calling the create_socket method.
Aside from the default 'low-level' event handlers, (for
read, write, and expt), there
are a few extra implied events that are captured by the
asyncore.dispatcher class for you.
handle_read: called whenever the socket has more
data to be read, meaning that recv() can be called
with an expectation of success.
handle_write: called whenever a socket is ready to
be written to - a call to send() can be expected
to succeed.
handle_oob: called when out-of-band data is present.
handle_accept: called when a new connection has been
accepted on a listening socket.
handle_connect: called when an outgoing
connect() has succeeded.
handle_close: called when the socket has closed.
asynchat.async_chat, provides support
for typical command/response protocols like SMTP, NNTP, FTP, etc...
It helps solve several problems for you:
'\r\n'
and '\r\n.\r\n' as terminators, the latter being
a common end-of-message delimiter.
You can change the current terminator by calling the
set_terminator method. Input is accumulated by
calling your own collect_incoming_data method.
When the terminator is located, the
found_terminator method is called.
send(),
async_chat first wraps the data in a simple
producer, called (strangely enough)
'simple_producer':
class simple_producer:
def __init__ (self, data):
self.data = data
def more (self):
if len (self.data) > 512:
result = self.data[:512]
self.data = self.data[512:]
return result
else:
result = self.data
self.data = ''
return result
Each producer must have a more() method, which is called
whenever more output is needed. Note how the data is deliberately
sent in fixed-size chunks: If you create a
simple_producer with a 15-Megabyte long string
(ghastly!), this will keep that one socket from monopolizing the
whole program. When the producer is exhausted, it returns an empty
string, like a file object signifying an end-of-file condition.
A producer can compute its output 'on-the-fly', if so desired. It can keep state information, too, like a file pointer, a database index, or a partial computation.
Each producer is filed into a queue (fifo), which is progressively emptied.
The more method of the front-most element of the queue is
called until it is exhausted, and then the producer is popped off the queue.
The combination of delimiting the input and scheduling the output
with a fifo allows you to design a server that will correctly handle
an impatient client. For example, some NNTP clients send a barrage of
commands to the server, and then count out the responses as they are
made (rather than sending a command, waiting for a response, etc...).
If a call to recv() reveals a buffer
full of these impatient commands, async_chat will handle the situation
correctly, calling collect_incoming_data and
found_terminator in sequence for each command.
The following discussion assumes a basic familiarity with socket programming
We'll start with a simple async finger client. Finger is a trivial tcp protocol that's completely stateless. You just connect to the finger port, send a request line, and read until the connection closes. [This is very similar to HTTP, by the way]
import socket import asyncore import string
# simple demo of the asyncore dispatcher class. class finger_client (asyncore.dispatcher): def __init__ (self, account, done_fun, long=1): self.name, self.host = tuple(string.split (account, '@')) self.done_fun = done_fun self.data = '' self.long = long self.create_socket (socket.AF_INET, socket.SOCK_STREAM) asyncore.dispatcher.__init__ (self) self.connect ((host, 79))
done_fun is a function that will be called when the
finger server has sent all the data and closed the connection. [this
programming style - passing functions around that represent an
execution path - is called continuation-passing style]
The call to create_socket will register the socket with
the underlying event mechanism, enabling the following callback
procedures.
# once connected, send the account name
def handle_connect (self):
self.log ('connected')
if self.long:
# this requests 'long' output.
self.send ('/w %s\r\n' % self.name)
else:
self.send ('%s\r\n' % self.name)
This function is called when the socket has made a connection. This
tells us that we can now send the finger request.
# collect some more finger server output.
def handle_read (self):
more = self.recv(512)
if not more:
self.handle_close()
self.data = self.data + more
When data is available for reading on the socket, this callback will
collect it into the member variable self.data
# the other side closed, we're done.
def handle_close (self):
print ''
self.done_fun (self.data)
self.close()
Now that we're all done, call the user's done_fun with
the finger data as an argument.
def demo_done_fun (stuff):
print stuff
def demo (who='asynfingdemo@squirl.nightmare.com'):
f = finger_client (who, demo_done_fun, long=0)
asyncore.loop()
The call to asyncore.loop() kicks of the default select
loop, one that will run until its list of channels becomes empty.
Once the finger client connection closes, the loop will exit,
returning control to the interpreter.
[Go ahead and try this one, I'm counting my readership with a python script]
pop3.py consumer.py.
ftp.py ftpgrab.py ftp.py; shows how to use
an async client class to build a useful program. This one allows you to simultaneously
grab many files from different servers from the command line.
asynhttp.py asyncore.dispatcher-based http client. It's not much
of an http client, though: it neither sends or processes HTTP
headers - it merely sends a 'GET' command and collects
the output.
servhttp.py 'GET' command and capable only
of delivering files. Just like the HTTP server that is now part of
the python distribution, though, it is easily extensible. What
makes this server interesting is its performance: In a bit of
informal testing against apache 0.6.2, it seems to be
able to handle a substantially higher number of hits, with a much
lower load on the machine. See the file 'abuse.py' for
more information and timings.
Historical Note: Medusa grew, starting in March 1996, from experimentation with this sample program. Medusa is a full-fledged TCP/IP server platform built upon the principles (and library) described here.
async_chat; I have built a fully RFC977-compliant (plus
all common extensions) NNTP server, and several other sophisticated
NNTP retrieval/filter engines. (If you'd like to see some of these as
examples, drop me a note).
On Unix, the arguments to select() are not limited to tcp
sockets, they can in fact be any file descriptor - including such
objects as unix domain sockets, pipes and fifos. This means that the
library can be used to communicate with these objects efficiently.
To do this, it is necessary to make sure that these descriptors are placed
in non-blocking mode. There are also a few API differences - the non-socket
objects will need to use read() and write(), rather
than recv() and send(). Simple support for this
is provided in the class asyncore.py:file_dispatcher
Work with this library has taken me down an interesting path. One
strange and exciting fork has been some experimentation in other
languages with a feature called 'first-class continuations'. A
first-class continuation is an object that captures the current state
of a program in such a way that it can be stored away and invoked
later, even invoked multiple times. This feature is an extremely
powerful tool for changing the control flow of a program. Usually
delivered to the user as a function,
call-with-current-continuation
(a.k.a. 'call/cc') in languages like Scheme and ML, it
can be used to write asynchronous programs that look
synchronous; in effect, call/cc allows one to write
programs in a multi-threaded style, but without using an
operating-system-supplied thread capability (the technical term is
'coroutines'). call/cc can also be used to synthesize
all other known higher-level control structures, such as Python and
C++-style exception handling.
There is some chance that Python will gain this wonderful feature, and I await the day anxiously. In the meanwhile, something along these lines has been written using the Gambit Scheme compiler. Here is some code that implements a portable socket interface to Gambit, and a coroutine-based socket-event 'scheduler'.
For more information on call/cc, see
the Revised^4 Report on Scheme
asyncore and asynchat modules to C++ classes
has been written (see the 'cpp' directory). It hasn't been tested
extensively, but appears to work as advertised. The code makes
heavy use of the up-and-coming 'Standard C++ Library', including
the string classes and STL. It can be very difficult to compile,
because most vendor's implementations of these features are in flux
(i.e., buggy as hell - for instance, juggling the order and naming of
include files can keep the source from compiling). The provided code
has been tested with Microsoft Visual C++ Version 4.2 on Win32, and
with the GNU C++ compiler and library version 2.7.2.
Sam Rushing / rushing@nightmare.com